
2021.11.12 23:52:34
我看的是机械工业出版社的算法导论(Introduction to Algorithms),据说不错。下面是我的读书笔记。
最近又找了本书看,笔记做一块算了
创建一个桶,将待排序的值按照某项值放到对应的桶中,即排序完成。按桶的下标顺序输出即可得到排序后结果:
data = [1,2,3,3,5,3,5]
arr = [0 for i in range(min(data),max(data))]
for i in arr:
# put data in bucket
arr[i]++;
## echo result
for i in arr:
for j in range(i):
print(i)因为读取即排序,所以速度非常快,时间复杂度为O(M+N)。M是桶长度,N是数据长度。
依赖下标顺序,因此数值过大时会过于浪费空间。
像冒泡一样反复按顺序比较两个相邻值,顺序错误则交换二者。
data = [...]
for i in range(data.length-1):
for j in range(i,data.length-1):
# exchange nearby value, to bigger
if data[j]>data[j+1]:
data[j],data[j+1]=data[j+1],data[j]名字好听
时间复杂度太高,达到O(n^2)
采用分治思想的排序算法。将数据二分并选择基准数,使左侧数都小于基准数,右侧均大于基准数。
对于二分后的子序列,继续使用相同的方法处理即可,也就是递归处理。
data = [...]
def QUICK_SORT(data,i,j):
base,end = i++,j
while i<j:
while data[j]>data[base]:
j--
while data[i]<data[base] and:
i++
data[i],data[j]=data[j],data[i]
data[base],data[j]=data[j],data[base]
if end-base>3:
QUICK_SORT(data,base,i)
QUICK_SORT(data,i,end)平均时间复杂度较低平均为O(NlogN),且节省空间。
速度取决于基准值的选择,最慢为O(N^2)
它在处理小规模数据时很有效。过程类似于我们抽取扑克牌:先摸一张,将它和手上的牌从左到右比大小并插入到正确的位置。这样,我们手中的牌就始终是排序好的。
下面是它的代码。
原书是伪代码,我翻译成C语言了
void insertion_sort(int* arr,int arrSize)
{
for(int j=2;j<arrSize;j++)
{
int i,key=arr[j];
i=j-1;
while(i>0&&arr[i]>key)
{
arr[i+1]=arr[i];
i--;
}
arr[i+1]=key;
}
}先入先出的数据结构。有两个操作,入队和出队。第一个入队的也是第一个出队的。
// struct defination
typedef struct{
int data[64];
int head=0,tail=0;
}Queue;
int pop(Queue *q){
if(*q && q->head < q->tail){
return q->data[q->head++];
}else{
return NULL;
}
}
int push(Queue *q, int data){
if(*q && q->tail < 63){
q->data[q->tail++] = data;
}else{
return NULL;
}
}可以看到,这种队列需要预先分配好空间,不太灵活,后面可以用链表优化这种结构。
先入后出的数据结构。同样有push和pop的操作。
typedef struct{
int data[64];
int top=0;
}Stack;
int pop(Stack* s){
if(*s && s->top>0){
return s->data[s->top--];
}else{
return NULL;
}
}
int push(Stack* s, int data){
if(*s && s->top<64){
return s->data[s->top++]=data;
}else
{
return NULL;
}
}一个非常灵活,但相比于数组不具有随机访问能力的数据结构。
typedef struct node{
int data;
node* next;
}Node;上面是链表节点的结构。包含指向下个节点的指针和数据。链表支持CRUD(创建,查询,修改,删除)操作,时间复杂度是常数。
略
类似于树的遍历,先沿着一个方向遍历,到头后返回上一个节点,遍历另一条路径。其核心思想是“这一步应该怎么做”,而下一步的做法和这一步是一样的:
data = [...]
nodes = set('abcdef')
def dfs(data, node, pos=0, result=''):
def verify(res):
# your code here...
pass
# current position is the next of last element of array
if pos==data.length:
if (verify(result)):
print(result)
else:
for i in node:
dfs(data, node-i, pos+1, result+i)
dfs(data, nodes)代码和实现都很简洁
很明显,因为采用了递归,所以有很高的时间复杂度
核心思想是“扩展”。对于一个数据空间(可能是各种数据结构),以一个样本为起点,向周围所有可拓展的数据点拓展,并对已经处理过的数据点进行标记。这个点处理过后,将这个数据点从处理队列中消去,并对新拓展的数据点进行相同处理。
每次处理时对数据点进行判断,将最符合条件的数据点进行存储即可。
下面是一种代码框架(大写的部分是伪代码):
map = [[0 for i in range(5)] for j in range(5)]
queue = {head:1,
tail:2,
data:[(0,0)]} # start point of bfs
directions = ((0,1),(1,0),(-1,0),(0,-1))
while queue.head<queue.tail:
for direction in directions:
p = queue.data[head]+direction
if IS_VALID(p) and not MAPPED(p):
MARK(p)
queue.data[tail++]=p
if REACH_RESULT(P):
flag=1
break
if flag==1:
break
head++
## print valid data point
printf(queue.data[tail])图由两个部分构成;
图的遍历就是指把图的每一个顶点都访问一次。由DFS方法访问图的所有顶点,并按照访问顺序对顶点标号,这标号就称为时间戳(timestamp)。
图的邻接矩阵存储法:一般使用一个大小为节点数平方的矩阵存储图:\(a_(ij)\)表示图的i节点和j节点的联通情况。1表示有边,无穷表示没有边,0表示到自己。
这里注意,无向图的矩阵是沿主对角线对称的。无向表示边的联通是双向的,有向则表示图是单向联通的。
使用DFS遍历图很简单:
e = [[...]...] # array for a graph with n elements
map = [0 for i in range(n)] # map: record checked node
def dfs(cur,sum=0): # cur: id of current node
print(cur)
if ++sum == n:
return
for i in range(1,n):
if e[cur][i] == 1 and map[i]==0:
map[i]=1
dfs(i,sum)
return
dfs(1) # check all nodes from node#1使用BFS遍历图也很简单:
大致流程:从一个点开始,将它的相邻点放入处理队列,然后弹出它自身;再对下一个点进行处理,直到所有的点都被遍历。
代码随后写
图的边可以是单向的,也可以是双向的,在矩阵中相应修改即可。图中有一个计算最短路径的问题(也就是给图的边加上不同的权重),可以使用DFS算法解决。不过一定要注意标记当前路径处理过的顶点,防止出现死循环。
同样,也可以用BFS算法遍历图。和DFS一样,这种算法可以计算出最少边数的图,且耗时更短,而DFS则需要完全遍历后才能得到结果,在效率上低一些,且数据量越大越明显。
我们可以得出结论:深度优先能处理权重图的搜索和无权重图的搜索;而广度优先在无权重图搜索上速度更快。
动态规划(dynamic programming,此处programming指表格法)和分治策略比较相似,都是通过组合子问题的解来求得原问题。唯一的区别是,分治算法的划分得到的是一组互不相关的子问题,动态规划得到的则是一组重叠的子问题。它的优势是使用了表格保存每个子问题的解,从而因为不会重复求解而减少了大量的计算量。
一个比较直观的例子就是计算费波纳契数列的算法。一般大家都会根据定义写出一个递推的算法,但是当问题比较大的时候,每展开一级,运算量都会呈指数级增加。但是如果缓存每一级的计算结果,那么就能直接将这个算法的复杂度降低到线性级别。
动态规划常用来解决最优化问题,这类问题有很多可行解,我们希望找出其中的一个具有最优值的解。
精髓在于:利用子问题的结果去求解当前问题。比如01背包问题,假设前面n-1个物品已经考虑完毕,那么考虑第n个物品要不要放入背包:假设背包总容量为\(W\),那么放入的话,背包的容量就会减为\(W-w_i\),不放入的话背包容量就还是\(W\)。假设我们使用\(dp[i][j]\)代表:考虑前\(i\)个物品,且背包最大容量为\(j\)时的最大价值,那么我们会发现,我们要求解的问题就是求解这个\(dp[i][j]\)。
同时我们发现,
\[ dp[i][j]=max(dp[i-1][j],dp[i-1][j-item[i].weight] + item[i].value) \]
也就是说,规模为\(dp[i][j]\)时的问题,其结果只与规模更小的子问题\(dp[i-1][j]\)和\(dp[i-1][j-item[i].value]\)有关。而对于这两个更小规模的子问题,我们又可以迭代/递归对它们进行求解。
将它展开成二维矩阵的形式,我们会发现它的求解顺序是很规律的,可以很轻易地以迭代的形式进行求解。
步骤:
memo-cut-rod(p, n) {
let r[0..n] = new array
r.forEach((index, _)=>r.[i]=-\infty)
return memo-cut-rod-aux(p, n, r)
}
memo-cut-rod-aux(p, n, r) {
if r[n]>=0 return r[n]
q = if (n==0) then 0 else -\infty
for i=1 to n:
q=max(q, memo-cut-rod-aux(p, n-1, r)+p[i])
r[n] = q
return q
}这方法要求求解顺序必须是按照问题规模从小到大进行的。其中,r[i]是用于保存规模为i的问题的求解结果的。
bottom-up-cut-rod(p, n) {
let r[0..n] = new array
r[0]=0
for j=1 to n {
for r[j]=-\infty; i=1 to j {
r[j]=max(r[j],p[i]+r[j-i])
}
}
return r[n]
}用于解决动态连通性问题,能动态连接两个点,并且判断两个点是否连通。
| 方法 | 描述 |
|---|---|
| UF(int N) | 构造一个大小为 N 的并查集 |
| void union(int p, int q) | 连接 p 和 q 节点 |
| int find(int p) | 查找 p 所在的连通分量编号 |
| boolean connected(int p, int q) | 判断 p 和 q 节点是否连通 |
public abstract class UF {
protected int[] id;
public UF(int N) {
id = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
}
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public abstract int find(int p);
public abstract void union(int p, int q);
}可以快速进行 find 操作,也就是可以快速判断两个节点是否连通。
需要保证同一连通分量的所有节点的 id 值相等。id 数组用来表示节点所在的连通分量
但是 union 操作代价却很高,需要将其中一个连通分量中的所有节点 id 值都修改为另一个节点的 id 值。
访问数组次数:判断是否联通需要 2 次读操作,union 获取联通分量需要2次读操作,遍历需要size 次读操作,修改需要 x 次写操作
size + 4 + x

public class QuickFindUF extends UF {
public QuickFindUF(int N) {
super(N);
}
@Override
public int find(int p) {
return id[p];
}
@Override
public void union(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID) {
return;
}
for (int i = 0; i < id.length; i++) {
if (id[i] == pID) {
id[i] = qID;
}
}
}
}可以快速进行 union 操作,只需要修改一个节点的 id 值即可。
但是 find 操作开销很大,因为同一个连通分量的节点 id 值不同,id 值只是用来指向另一个节点。因此需要一直向上查找操作,直到找到最上层的节点。 id数组中记录同一个分量中的另一个节点名称,根节点连接指向自己
2*两个待合并子树的深度和 + 1

public class QuickUnionUF extends UF {
public QuickUnionUF(int N) {
super(N);
}
@Override
public int find(int p) {
while (p != id[p]) {
p = id[p];
}
return p;
}
@Override
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot != qRoot) {
id[pRoot] = qRoot;
}
}
}这种方法可以快速进行 union 操作,但是 find 操作和树高成正比,最坏的情况下树的高度为节点的数目。

为了解决 quick-union 的树通常会很高的问题,加权 quick-union 在 union 操作时会让较小的树连接较大的树上面。
理论研究证明,加权 quick-union 算法构造的树深度最多不超过 logN。
2*两个待合并子树的深度和 + 4

public class WeightedQuickUnionUF extends UF {
// 保存节点的数量信息
private int[] sz;
public WeightedQuickUnionUF(int N) {
super(N);
this.sz = new int[N];
for (int i = 0; i < N; i++) {
this.sz[i] = 1;
}
}
@Override
public int find(int p) {
while (p != id[p]) {
p = id[p];
}
return p;
}
@Override
public void union(int p, int q) {
int i = find(p);
int j = find(q);
if (i == j) return;
if (sz[i] < sz[j]) {
id[i] = j;
sz[j] += sz[i];
} else {
id[j] = i;
sz[i] += sz[j];
}
}
}在检查节点的同时将它们直接链接到根节点,只需要在 find 中添加一个循环即可。
while (id[p] != p){
id[p] = id[id[p]];
p = id[p];
}| 算法 | union | find |
|---|---|---|
| Quick Find | N | 1 |
| Quick Union | 树高 | 树高 |
| 加权 Quick Union | logN | logN |
| 路径压缩的加权 Quick Union | 非常接近 1 | 非常接近 1 |
对数图像:(log-log plot)
对于一个算法,如果其运行时间和数据规模有如下关系: \[ T ( N ) = a N ^ { b } \] 对运行时间和数据规模都取对数,可以得到如下关系: \[ \lg ( T ( N ) ) = b \lg N + c \\a=2^c \] 图像的斜率为 b,
倍率实验:因此,如果 T(n) ~ an^b ,可以采用数据量加倍,测量运行时间,求对数斜率的方法对 ab 进行估算,但注意这种方法无法用来估计存在对数关系的计算复杂度。
~,数组访问,比较次数抹掉低阶项但系数保留
选择出数组中的最小元素,将它与数组的第一个元素交换位置。再从剩下的元素中选择出最小的元素,将它与数组的第二个元素交换位置。不断进行这样的操作,直到将整个数组排序。
选择排序需要 ~N2/2 次比较和 ~N 次交换,它的运行时间与输入无关,这个特点使得它对一个已经排序的数组也需要这么多的比较和交换操作。

public class Selection<T extends Comparable<T>> extends Sort<T> {
@Override
public void sort(T[] nums) {
int N = nums.length;
for (int i = 0; i < N - 1; i++) {
int min = i;
for (int j = i + 1; j < N; j++) {
if (less(nums[j], nums[min])) {
min = j;
}
}
swap(nums, i, min);
}
}
}从左到右不断交换相邻逆序的元素,在一轮的循环之后,可以让未排序的最大元素上浮到右侧。
在一轮循环中,如果没有发生交换,就说明数组已经是有序的,此时可以直接退出。
以下演示了在一轮循环中,将最大的元素 5 上浮到最右侧。

public class Bubble<T extends Comparable<T>> extends Sort<T> {
@Override
public void sort(T[] nums) {
int N = nums.length;
boolean hasSorted = false;
for (int i = N - 1; i > 0 && !hasSorted; i--) {
hasSorted = true;
for (int j = 0; j < i; j++) {
if (less(nums[j + 1], nums[j])) {
hasSorted = false;
swap(nums, j, j + 1);
}
}
}
}
}每次都将当前元素插入到左侧已经排序的数组中,使得插入之后左侧数组依然有序。
对于数组 {3, 5, 2, 4, 1},它具有以下逆序:(3, 2), (3, 1), (5, 2), (5, 4), (5, 1), (2, 1), (4, 1),插入排序每次只能交换相邻元素,令逆序数量减少 1,因此插入排序需要交换的次数为逆序数量。
插入排序的复杂度取决于数组的初始顺序,如果数组已经部分有序了,逆序较少,那么插入排序会很快。
以下演示了在一轮循环中,将元素 2 插入到左侧已经排序的数组中。

public class Insertion<T extends Comparable<T>> extends Sort<T> {
@Override
public void sort(T[] nums) {
int N = nums.length;
for (int i = 1; i < N; i++) {
for (int j = i; j > 0 && less(nums[j], nums[j - 1]); j--) {
swap(nums, j, j - 1);
}
}
}
}对于大规模的数组,插入排序很慢,因为它只能交换相邻的元素,每次只能将逆序数量减少 1。
希尔排序的出现就是为了解决插入排序的这种局限性,它通过交换不相邻的元素,每次可以将逆序数量减少大于 1。
希尔排序使用插入排序对间隔 h 的序列进行排序。通过不断减小 h,最后令 h=1,就可以使得整个数组是有序的。

public class Shell<T extends Comparable<T>> extends Sort<T> {
@Override
public void sort(T[] nums) {
int N = nums.length;
int h = 1;
while (h < N / 3) {
h = 3 * h + 1; // 1, 4, 13, 40, ...
}
while (h >= 1) {
for (int i = h; i < N; i++) {
for (int j = i; j >= h && less(nums[j], nums[j - h]); j -= h) {
swap(nums, j, j - h);
}
}
h = h / 3;
}
}
}希尔排序的运行时间达不到平方级别,使用递增序列 1, 4, 13, 40, … 的希尔排序所需要的比较次数不会超过 N 的若干倍乘于递增序列的长度。后面介绍的高级排序算法只会比希尔排序快两倍左右。
归并排序的思想是将数组分成两部分,分别进行排序,然后归并起来。

归并方法将数组中两个已经排序的部分归并成一个。
public abstract class MergeSort<T extends Comparable<T>> extends Sort<T> {
protected T[] aux;
protected void merge(T[] nums, int l, int m, int h) {
//将aux[lo,mid] 和 aux[m+1,h]归并
int i = l, j = m + 1;
for (int k = l; k <= h; k++) {
aux[k] = nums[k]; // 将数据复制到辅助数组
}
for (int k = l; k <= h; k++) {
if (i > m) { //左边用尽
nums[k] = aux[j++];
} else if (j > h) { // 右边用尽
nums[k] = aux[i++];
} else if (aux[i].compareTo(nums[j]) <= 0) { //左比右小
nums[k] = aux[i++]; // 先进行这一步,保证稳定性
} else { //左比右大
nums[k] = aux[j++];
}
}
}
}将一个大数组分成两个小数组去求解。
因为每次都将问题对半分成两个子问题,这种对半分的算法复杂度一般为 O(NlogN)。
public class Up2DownMergeSort<T extends Comparable<T>> extends MergeSort<T> {
@Override
public void sort(T[] nums) {
aux = (T[]) new Comparable[nums.length];
sort(nums, 0, nums.length - 1);
}
private void sort(T[] nums, int l, int h) {
if (h <= l) {
return;
}
int mid = l + (h - l) / 2;
sort(nums, l, mid);
sort(nums, mid + 1, h);
merge(nums, l, mid, h);
}
}先归并那些微型数组,然后成对归并得到的微型数组。
public class Down2UpMergeSort<T extends Comparable<T>> extends MergeSort<T> {
@Override
public void sort(T[] nums) {
int N = nums.length;
aux = (T[]) new Comparable[N];
for (int sz = 1; sz < N; sz += sz) { //每一趟归并的数组大小
for (int lo = 0; lo < N - sz; lo += sz + sz) {
merge(nums, lo, lo + sz - 1, Math.min(lo + sz + sz - 1, N - 1));
}
}
}
}
public class QuickSort<T extends Comparable<T>> extends Sort<T> {
@Override
public void sort(T[] nums) {
shuffle(nums);
sort(nums, 0, nums.length - 1);
}
private void sort(T[] nums, int l, int h) {
if (h <= l)
return;
int j = partition(nums, l, h);
sort(nums, l, j - 1);
sort(nums, j + 1, h);
}
private void shuffle(T[] nums) {
List<Comparable> list = Arrays.asList(nums);
Collections.shuffle(list);
list.toArray(nums);
}
}取 a[l] 作为切分元素,然后从数组的左端向右扫描直到找到第一个大于等于它的元素,再从数组的右端向左扫描找到第一个小于它的元素,交换这两个元素。不断进行这个过程,就可以保证左指针 i 的左侧元素都不大于切分元素,右指针 j 的右侧元素都不小于切分元素。当两个指针相遇时,将切分元素 a[l] 和 a[j] 交换位置。

private int partition(T[] nums, int l, int h) {
int i = l, j = h + 1;
T v = nums[l];
while (true) {
while (less(nums[++i], v) && i != h) ;
while (less(v, nums[--j]) && j != l) ;
if (i >= j)
break;
swap(nums, i, j);
}
swap(nums, l, j);
return j;
}快速排序是原地排序,不需要辅助数组,但是递归调用需要辅助栈。
快速排序最好的情况下是每次都正好将数组对半分,这样递归调用次数才是最少的。这种情况下比较次数为 CN=2CN/2+N,复杂度为 O(NlogN)。
最坏的情况下,第一次从最小的元素切分,第二次从第二小的元素切分,如此这般。因此最坏的情况下需要比较 N2/2。为了防止数组最开始就是有序的,在进行快速排序时需要随机打乱数组。
因为快速排序在小数组中也会递归调用自己,对于小数组,插入排序比快速排序的性能更好,因此在小数组中可以切换到插入排序。
最好的情况下是每次都能取数组的中位数作为切分元素,但是计算中位数的代价很高。一种折中方法是取 3 个元素,并将大小居中的元素作为切分元素。
对于有大量重复元素的数组,可以将数组切分为三部分,分别对应小于、等于和大于切分元素。
三向切分快速排序对于有大量重复元素的随机数组可以在线性时间内完成排序。
public class ThreeWayQuickSort<T extends Comparable<T>> extends QuickSort<T> {
@Override
protected void sort(T[] nums, int l, int h) {
if (h <= l) {
return;
}
int lt = l, i = l + 1, gt = h;
T v = nums[l];
while (i <= gt) {
int cmp = nums[i].compareTo(v);
if (cmp < 0) {
swap(nums, lt++, i++);
} else if (cmp > 0) {
swap(nums, i, gt--);
} else {
i++;
}
}
sort(nums, l, lt - 1);
sort(nums, gt + 1, h);
}
}快速排序的 partition() 方法,会返回一个整数 j 使得 a[l..j-1] 小于等于 a[j],且 a[j+1..h] 大于等于 a[j],此时 a[j] 就是数组的第 j 大元素。
可以利用这个特性找出数组的第 k 个元素。
该算法是线性级别的,假设每次能将数组二分,那么比较的总次数为 (N+N/2+N/4+..),直到找到第 k 个元素,这个和显然小于 2N。
public T select(T[] nums, int k) {
int l = 0, h = nums.length - 1;
while (h > l) {
int j = partition(nums, l, h);
if (j == k) {
return nums[k];
} else if (j > k) {
h = j - 1;
} else {
l = j + 1;
}
}
return nums[k];
}堆中某个节点的值总是大于等于其子节点的值,并且堆是一颗完全二叉树。
堆可以用数组来表示,这是因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。这里不使用数组索引为 0 的位置,是为了更清晰地描述节点的位置关系。

public class Heap<T extends Comparable<T>> {
private T[] heap;
private int N = 0;
public Heap(int maxN) {
this.heap = (T[]) new Comparable[maxN + 1];
}
public boolean isEmpty() {
return N == 0;
}
public int size() {
return N;
}
private boolean less(int i, int j) {
return heap[i].compareTo(heap[j]) < 0;
}
private void swap(int i, int j) {
T t = heap[i];
heap[i] = heap[j];
heap[j] = t;
}
}在堆中,当一个节点比父节点大,那么需要交换这个两个节点。交换后还可能比它新的父节点大,因此需要不断地进行比较和交换操作,把这种操作称为上浮。

private void swim(int k) {
while (k > 1 && less(k / 2, k)) {
swap(k / 2, k);
k = k / 2;
}
}类似地,当一个节点比子节点来得小,也需要不断地向下进行比较和交换操作,把这种操作称为下沉。一个节点如果有两个子节点,应当与两个子节点中最大那个节点进行交换。

private void sink(int k) {
while (2 * k <= N) {
int j = 2 * k;
if (j < N && less(j, j + 1))
j++;
if (!less(k, j))
break;
swap(k, j);
k = j;
}
}将新元素放到数组末尾,然后上浮到合适的位置。
public void insert(Comparable v) {
heap[++N] = v;
swim(N);
}从数组顶端删除最大的元素,并将数组的最后一个元素放到顶端,并让这个元素下沉到合适的位置。
public T delMax() {
T max = heap[1];
swap(1, N--);
heap[N + 1] = null;
sink(1);
return max;
}把最大元素和当前堆中数组的最后一个元素交换位置,并且不删除它,那么就可以得到一个从尾到头的递减序列,从正向来看就是一个递增序列,这就是堆排序。
无序数组建立堆最直接的方法是从左到右遍历数组进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。

交换之后需要进行下沉操作维持堆的有序状态。


public class HeapSort<T extends Comparable<T>> extends Sort<T> {
/**
* 数组第 0 个位置不能有元素
*/
@Override
public void sort(T[] nums) {
int N = nums.length - 1;
for (int k = N / 2; k >= 1; k--)
sink(nums, k, N);
while (N > 1) {
swap(nums, 1, N--);
sink(nums, 1, N);
}
}
private void sink(T[] nums, int k, int N) {
while (2 * k <= N) {
int j = 2 * k;
if (j < N && less(nums, j, j + 1))
j++;
if (!less(nums, k, j))
break;
swap(nums, k, j);
k = j;
}
}
private boolean less(T[] nums, int i, int j) {
return nums[i].compareTo(nums[j]) < 0;
}
}一个堆的高度为 logN,因此在堆中插入元素和删除最大元素的复杂度都为 logN。
对于堆排序,由于要对 N 个节点进行下沉操作,因此复杂度为 NlogN。
堆排序是一种原地排序,没有利用额外的空间。
现代操作系统很少使用堆排序,因为它无法利用局部性原理进行缓存,也就是数组元素很少和相邻的元素进行比较和交换。
| 算法 | 稳定性 | 时间复杂度 | 空间复杂度 | 备注 |
|---|---|---|---|---|
| 选择排序 | × | N2 | 1 | |
| 冒泡排序 | √ | N2 | 1 | |
| 插入排序 | √ | N ~ N2 | 1 | 时间复杂度和初始顺序有关 |
| 希尔排序 | × | N 的若干倍乘于递增序列的长度 | 1 | 改进版插入排序 |
| 快速排序 | × | NlogN | logN(递归) | |
| 三向切分快速排序 | × | N ~ NlogN | logN | 适用于有大量重复主键 |
| 归并排序 | √ | NlogN | N | |
| 堆排序 | × | NlogN | 1 | 无法利用局部性原理 |
快速排序是最快的通用排序算法,它的内循环的指令很少,而且它还能利用缓存,因为它总是顺序地访问数据。它的运行时间近似为 ~cNlogN,这里的 c 比其它线性对数级别的排序算法都要小。
使用三向切分快速排序,实际应用中可能出现的某些分布的输入能够达到线性级别,而其它排序算法仍然需要线性对数时间。
| 排序方法 | 平均时间 | 最好时间 | 最坏时间 |
|---|---|---|---|
| 桶排序(不稳定) | O(n) | O(n) | O(n) |
| 基数排序(稳定) | O(n) | O(n) | O(n) |
| 归并排序(稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 快速排序(不稳定) | O(nlogn) | O(nlogn) | O(n^2) |
| 堆排序(不稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 希尔排序(不稳定) | O(n^1.25) | ||
| 冒泡排序(稳定) | O(n^2) | O(n) | O(n^2) |
| 选择排序(不稳定) | O(n^2) | O(n^2) | O(n^2) |
| 直接插入排序(稳定) | O(n^2) | O(n) | O(n^2) |
Java 主要排序方法为 java.util.Arrays.sort(),对于原始数据类型使用三向切分的快速排序,对于引用类型使用归并排序。
最小生成树:在一个有n个节点的连通图中,生成一棵连通所有顶点且顶点间边的权重之和最小的树。
切分定理: 在一幅加权图中,给定任意的切分,他的横切边中权重最小者必然属于图的最小生成树
在连通图中,基于边和顶点考虑有两个基本的算法可以生成最小生成树:
Prim算法的核心思想是:每次迭代都是在连通图中搜索离生成树最近的顶点X并将其添加进生成树。其中,离生成树最近表示顶点X相较于其它不在生成树中的顶点距离生成树最近。
Prim算法是用于解决最小生成树的算法之一,算法的每一步都会为一棵生长中的树添加一条边.一开始这棵树只有一个顶点,然后会一直添加到\(V -
1\)条边,每次总是将下一条连接树中的顶点与不在树中的顶点且权重最小的边加入到树中(也就是由树中顶点所定义的切分中的一条横切边).
实现Prim算法还需要借助以下数据结构:
顶点是否已在树中.最小生成树中的边,也可以使用一个由顶点索引的Edge对象的数组.横切边,优先队列的性质可以每次取出权值最小的横切边.当我们连接新加入树中的顶点与其他已经在树中顶点的所有边都失效了(由于两个顶点都已在树中,所以这是一条失效的横切边).我们需要处理这种情况,即时实现对无效边采取忽略(不加入到优先队列中),而延时实现会把无效边留在优先队列中,等到要删除优先队列中的数据时再进行有效性检查.
上图为Prim算法延时实现的轨迹图,它的步骤如下:
顶点0添加到最小生成树中,将它的邻接表中的所有边添加到优先队列中(将横切边添加到优先队列).顶点7和边0-7添加到最小生成树中,将顶点的邻接表中的所有边添加到优先队列中.顶点1和边1-7添加到最小生成树中,将顶点的邻接表中的所有边添加到优先队列中.顶点2和边0-2添加到最小生成树中,将边2-3和6-2添加到优先队列中,边2-7和1-2失效.顶点3和边2-3添加到最小生成树中,将边3-6添加到优先队列之中,边1-3失效.顶点5和边5-7添加到最小生成树中,将边4-5添加到优先队列中,边1-5失效.1-3,1-5,2-7.顶点4和边4-5添加到最小生成树中,将边6-4添加到优先队列中,边4-7,0-4失效.1-2,4-7,0-4.顶点6和边6-2添加到最小生成树中,和顶点6关联的其他边失效.V个顶点与V - 1条边之后,最小生成树就构造完成了,优先队列中剩余的边都为失效边.public class LazyPrimMST {
private final EdgeWeightedGraph graph;
// 记录最小生成树的总权重
private double weight;
// 存储最小生成树的边
private final Queue<Edge> mst;
// 标记这个顶点在树中
private final boolean[] marked;
// 存储横切边的优先队列
private final PriorityQueue<Edge> pq;
public LazyPrimMST(EdgeWeightedGraph graph) {
this.graph = graph;
int vertex = graph.vertex();
mst = new ArrayDeque<>();
pq = new PriorityQueue<>();
marked = new boolean[vertex];
for (int v = 0; v < vertex; v++)
if (!marked[v]) prim(v);
}
private void prim(int s) {
scanAndPushPQ(s);
while (!pq.isEmpty()) {
Edge edge = pq.poll(); // 取出权重最小的横切边
int v = edge.either(), w = edge.other(v);
assert marked[v] || marked[w];
if (marked[v] && marked[w])
continue; // 忽略失效边
mst.add(edge); // 添加边到最小生成树中
weight += edge.weight(); // 更新总权重
// 继续将非树顶点加入到树中并更新横切边
if (!marked[v]) scanAndPushPQ(v);
if (!marked[w]) scanAndPushPQ(w);
}
}
// 标记顶点到树中,并且添加横切边到优先队列
private void scanAndPushPQ(int v) {
assert !marked[v];
marked[v] = true;
for (Edge e : graph.adj(v))
if (!marked[e.other(v)]) pq.add(e);
}
public Iterable<Edge> edges() {
return mst;
}
public double weight() {
return weight;
}
}在即时实现中,将v添加到树中时,对于每个非树顶点w,不需要在优先队列中保存所有从w到树顶点的边,而只需要保存其中权重最小的边,所以在将v添加到树中后,要检查是否需要更新这条权重最小的边(如果v-w的权重更小的话).
也可以认为只会在优先队列中保存每个非树顶点w的一条边(也是权重最小的那条边),将w和树顶点连接起来的其他权重较大的边迟早都会失效,所以没必要在优先队列中保存它们.
要实现即时版的Prim算法,需要使用两个顶点索引的数组edgeTo[]和distTo[]与一个索引优先队列,它们具有以下性质:
顶点v不在树中但至少含有一条边和树相连,那么edgeTo[v]是将v和树连接的最短边,distTo[v]为这条边的权重.顶点v都保存在索引优先队列中,索引v关联的值是edgeTo[v]的边的权重.权重最小的横切边的权重,而和它相关联的顶点v就是下一个将要被添加到树中的顶点.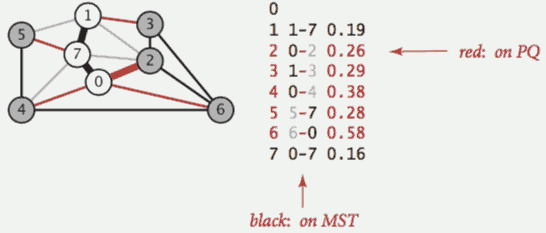
顶点0添加到最小生成树之中,将它的邻接表中的所有边添加到优先队列中(这些边是目前唯一已知的横切边).顶点7和边0-7添加到最小生成树,将边1-7和5-7添加到优先队列中,将连接顶点4与树的最小边由0-4替换为4-7.顶点1和边1-7添加到最小生成树,将边1-3添加到优先队列.顶点2和边0-2添加到最小生成树,将连接顶点6与树的最小边由0-6替换为6-2,将连接顶点3与树的最小边由1-3替换为2-3.顶点3和边2-3添加到最小生成树.顶点5和边5-7添加到最小生成树,将连接顶点4与树的最小边4-7替换为4-5.顶点4和边4-5添加到最小生成树.顶点6和边6-2添加到最小生成树.V - 1条边之后,最小生成树构造完成并且优先队列为空.public class PrimMST {
private final EdgeWeightedGraph graph;
// 存放最小生成树中的边
private final Edge[] edgeTo;
// 每条边对应的权重
private final double[] distTo;
private final boolean[] marked;
private final IndexMinPQ<Double> pq;
public PrimMST(EdgeWeightedGraph graph) {
this.graph = graph;
int vertex = graph.vertex();
this.edgeTo = new Edge[vertex];
this.marked = new boolean[vertex];
this.pq = new IndexMinPQ<>(vertex);
this.distTo = new double[vertex];
// 将权重数组初始化为无穷大
for (int i = 0; i < vertex; i++)
distTo[i] = Double.POSITIVE_INFINITY;
for (int v = 0; v < vertex; v++)
if (!marked[v]) prim(v);
}
private void prim(int s) {
// 将起点设为0.0并加入到优先队列
distTo[s] = 0.0;
pq.insert(s, distTo[s]);
while (!pq.isEmpty()) {
// 取出权重最小的边,优先队列中存的顶点是与树相连的非树顶点,
// 同时它也是下一次要加入到树中的顶点
int v = pq.delMin();
scan(v);
}
}
private void scan(int v) {
// 将顶点加入到树中
marked[v] = true;
for (Edge e : graph.adj(v)) {
int w = e.other(v);
// 忽略失效边
if (marked[w]) continue;
// 如果w与连接树顶点的边的权重小于其他w连接树顶点的边
// 则进行替换更新
if (e.weight() < distTo[w]) {
distTo[w] = e.weight();
edgeTo[w] = e;
if (pq.contains(w))
pq.decreaseKey(w, distTo[w]);
else
pq.insert(w, distTo[w]);
}
}
}
public Iterable<Edge> edges() {
Queue<Edge> mst = new ArrayDeque<>();
for (int v = 0; v < edgeTo.length; v++) {
Edge e = edgeTo[v];
if (e != null) {
mst.add(e);
}
}
return mst;
}
public double weight() {
double weight = 0.0;
for (Edge e : edges())
weight += e.weight();
return weight;
}
}不管是延迟实现还是即时实现,Prim算法的规律就是:
在树的生长过程中,都是通过连接一个和新加入的顶点相邻的顶点.当新加入的顶点周围没有非树顶点时,树的生长又会从另一部分开始.
Kruskal算法的思想是按照边的权重顺序由小到大处理它们,将边添加到最小生成树,加入的边不会与已经在树中的边构成环,直到树中含有V - 1条边为止.这些边会逐渐由一片森林合并为一棵树,也就是我们需要的最小生成树.
Prim算法是一条边一条边地来构造最小生成树,每一步都会为树中添加一条边.Kruskal算法构造最小生成树也是一条边一条边地添加,但不同的是它寻找的边会连接一片森林中的两棵树.从一片由V棵单顶点的树构成的森林开始并不断地将两棵树合并(可以找到的最短边)直到只剩下一棵树,它就是最小生成树.要实现Kruskal算法需要借助Union-Find数据结构,它是一种树型的数据结构,用于处理一些不相交集合的合并与查询问题.
关于Union-Find的更多资料可以参考下面的链接:
public class KruskalMST {
// 这条队列用于记录最小生成树中的边集
private final Queue<Edge> mst;
private double weight;
public KruskalMST(EdgeWeightedGraph graph) {
this.mst = new ArrayDeque<>();
// 创建一个优先队列,并将图的所有边添加到优先队列中
PriorityQueue<Edge> pq = new PriorityQueue<>();
for (Edge e : graph.edges()) {
pq.add(e);
}
int vertex = graph.vertex();
// 创建一个Union-Find
UF uf = new UF(vertex);
// 一条一条地添加边到最小生成树,直到添加了 V - 1条边
while (!pq.isEmpty() && mst.size() < vertex - 1) {
// 取出权重最小的边
Edge e = pq.poll();
int v = e.either();
int w = e.other(v);
// 如果这条边的两个顶点不在一个分量中(对于union-find数据结构中而言)
if (!uf.connected(v, w)) {
// 将v和w归并(对于union-find数据结构中而言),然后将边添加进树中,并计算更新权重
uf.union(v, w);
mst.add(e);
weight += e.weight();
}
}
}
public Iterable<Edge> edges() {
return mst;
}
public double weight() {
return weight;
}
}上面代码实现的Kruskal算法使用了一条队列来保存最小生成树的边集,一条优先队列来保存还未检查的边,一个Union-Find来判断失效边.
| 算法 | 空间复杂度 | 时间复杂度 |
|---|---|---|
| Prim(延时) | E | ElogE |
| Prim(即时) | V | ElogV |
| Kruskal | E | ElogE |
| 算法 | 所需结构 |
|---|---|
| Prime(Lazy) | 优先队列、队列MST(记录已经加入MST里面的边)、bool 数组(记录顶点是否已经加入MST) |
| Prime (eager) | 索引优先队列(K: 顶点 V: 顶点到MST的最小距离)、edgeto[] (记录到达 v的路径)、distTo[] (记录 v 到 MST 的距离,与索引优先队列里面的值相同) |
| Kruskal | 队列 (记录已经加入到 MST 里面的边)、优先队列(从中取出权值最小的边),UF (判断失效边) |
算法:
将 distTo[s] 初始化为 0,将distTo[] 中的其他元素初始化为正无穷
初始化索引优先队列
将(s,0)加入索引优先队列
从优先队列中取出值最小的顶点 e
遍历以该顶点为起点的每一条边 e,w ,放松每一条边
distTo[w] = distTo[v] + e.weight();同时维护优先队列
public class DijkstraSP {
private DirectedEdge[] edgeTo;
private double[] distTo;
private IndexMinPQ<Double> pq;
public DijkstraSP(EdgeWeightedDigraph G, int s) {
edgeTo = new DirectedEdge[G.V()];
distTo = new double[G.V()];
pq = new IndexMinPQ<Double>(G.V());
for (int v = 0; v < G.V(); v++)
distTo[v] = Double.POSITIVE_INFINITY;
distTo[s] = 0.0;
pq.insert(s, 0.0);
// relax vertices in order of distance from s
while (!pq.isEmpty())
{
int v = pq.delMin();
for (DirectedEdge e : G.adj(v))
relax(e);
}
}
private void relax(DirectedEdge e) {
int v = e.from(), w = e.to();
if (distTo[w] > distTo[v] + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
// update PQ
if (pq.contains(w)) pq.decreaseKey(w, distTo[w]);
else pq.insert (w, distTo[w]);
}
}
}时间复杂度:ElogV (V次插入操作,V次删除最小元素的操作、最坏情况下的 E 次改变优先级的操作,基于堆实现的优先队列这些操作的复杂度为 logV)
空间复杂度:V
将 distTo[] 数组元素初始化为无穷大,以任意顺序放松图的所有边,重复 V 轮
基于队列的 Bellman-Ford 算法
使用 FIFO 队列记录 distTo[] 值发生变换的顶点,在队列中加入发生了松弛操作的边的终点,从队列中依次取出这些顶点,遍历以这些顶点为起点的边,进行松弛,直到队列为空
| algorithm | restriction | typical case | worst case | extra space |
|---|---|---|---|---|
| topological sort | no directed cycles | E +V | E +V | V |
| Dijkstra (binary heap) | no negative weights | E log V | E log V | V |
| Bellman-Ford | no negative cycles | EV | EV | V |
| Bellman-Ford (queue-based) | no negative cycles | E+V | EV | V |