2023-07-21 20:32:36
其实理论上这玩意早都折腾好了。
只不过不满意于当时的家用板子(B450MK+1500X)对于ESXi兼容性太差,后来又换回了Windows+VMWare的组合。这组合咋用咋不爽,所以最后攒了点钱,整了一套服务器平台(联想的X99板子+E5 2680V4 x2+16G DDR4 ECC,一共大概600大洋),不过因为一些原因拖到最近才空出时间调试好。
本来机子6月已经装好了,但是一直处于开机不亮屏的状态。昨个跟卖家唠嗑了老久,调试了半天才发现这板子好像只知道集成显卡输出,就好像它不知道自己上边还插着个1080一样。
没办法,集显就集显吧,反正确实能用,还能省点电呢(=。=)
进了U盘,启动ESXi镜像,直接开装。因为是服务器板子,所以不用担心网卡支持之类的问题,反正很顺利地装完了。旁边的弱电柜看着挺好,里边还有个交换机来着,但是看到那密密麻麻的走线,折腾了一下就放弃了(而且这玩意要管理还得插串口线,笑死,根本找不到)。
于是直接把机器插到路由器上了。千兆网,爽死。
整好网络配置之后已经很晚了,遂直接回宿舍,来日再整。
昨天才装好ESXi,今天下午急冲冲跑到实验室装好了Ubuntu,然后想整个OpenWRT当旁路由,但是发现目前还没啥必要,于是作罢,就用Ubuntu直接开始吧(反正比Windows好
随便装了装软件啥的。先是试着用刚学的sed给apt换了个源,然后装了docker,zip啥的。有了docker之后,直接把笔记本上的mc服务器扔了上去+docker run光速部署。真香。
然后慢慢折腾回以前的服务。首先是gitea,1.20居然都支持ci/cd了,这不狠狠部署?但是我以前的数据还在硬盘上扔着,于是先整了下物理硬盘的vhd映射。下面记录一下:
打开ESXi的SecureSHell(ssh)服务之后,用它的管理账户密码登录上去,然后运行
ls /vmfs/devices/disks/查看系统挂载的硬盘信息:
t10.ATA_____ST2000DM0052D2CW102__________________________________WFL1DE7T
t10.ATA_____ST2000DM0052D2CW102__________________________________WFL1DE7T:1
t10.ATA_____ST2000DM0052D2CW102__________________________________WFL1DE7T:5
t10.ATA_____ST4000VX0002D2AG166__________________________________ZDHA1DHG
t10.ATA_____ST4000VX0002D2AG166__________________________________ZDHA1DHG:1
t10.ATA_____ST4000VX0002D2AG166__________________________________ZDHA1DHG:2
t10.NVMe____ORICO_V500_128GB________________________0000000000000001
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:1
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:2
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:3
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:5
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:6
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:7
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:8
t10.NVMe____ORICO_V500_128GB________________________0000000000000001:9
vml.010000000020202020202020202020202057464c3144453754535432303030
vml.010000000020202020202020202020202057464c3144453754535432303030:1
vml.010000000020202020202020202020202057464c3144453754535432303030:5
vml.01000000002020202020202020202020205a44484131444847535434303030
vml.01000000002020202020202020202020205a44484131444847535434303030:1
vml.01000000002020202020202020202020205a44484131444847535434303030:2
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:1
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:2
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:3
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:5
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:6
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:7
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:8
vml.0100000000303030305f303030305f303030305f30303031004f5249434f20:9然后找到硬盘对应的编号,然后用vmkfstools把硬盘映射到vhd文件里:
vmkfstools -z /vmfs/devices/disks/[target disk] /vmfs/voluems/datastore1/[target vhd link name].vmdk完成之后,在虚拟机编辑里添加硬盘,选择现有硬盘,在里边找到刚才新建的两个硬盘映射vhd文件。
挂载到虚拟机上之后,开机,我们还得把硬盘挂载到系统上。
硬盘加到虚拟机上之后,一般会以/dev/sd[a-z]的形式出现,这种时候只需要用fdisk康康磁盘上有什么好康的分区就行啦。不过我这盘好像被Windows的快速启动污染了,得先在Windows里挂载一下,正常关机才能挂载到Linux底下。
所以,现在本来要装Windows来着,但是突然发现Vmware里边有个叫上载虚拟机的东东:
然后就懒得装了,直接把以前的老虚拟机传上去了。开机前设置下硬盘挂载,然后直接开机再关机,搞定。
配置完成之后,发现果然还是另外整个系统当frp的客户端比较稳定。挑了半天发现还是OpenWRT最方便,于是在OpenWrt软路由固件下载与在线定制编译这里下了个x86架构的编译版本装上了。启动之后应该就能正常访问了,就是得先配置下网络的配置文件(我这边为了网络环境方便访问,配置的是bridge桥接模式,所以得手动重新设置网关、地址之类的)。配置相关的内容,恩山有不少内容可以参考。
总之一番折腾下来配好旁路由和内网穿透以及基本不咋用的局域网代理之后,折腾就基本结束了
直到我发现安装系统选项底下有个MacOS。装都装了,不试试怎么行呢(不过据了解,黑果在ESXi虚拟化环境下体验不行,更建议物理机
TODO:等啥时候加个ssd扩容系统盘再说吧。。空间居然不够用了
装完机器之后想配置宿主机启动后,子主机跟着自动启动。但是在机器的虚拟机设置里边开开了自动启动之后,却没有按照预期开机自动启动VM。排查一番之后发现原来还有个设置没开。
从左侧导航栏到主机->管理->系统->自动启动,点编辑设置,把自动启动打开就行。
这边的两个延时,指的是ESXi启动/关闭所有虚拟机的间隔时间,全局设置会被主机的设置覆盖。而等待检测信号(Wait for heartbeat)指的是,在VM中安装VMWare工具后,系统启动完成后会告知宿主机。此时,如果这个设置为真,则ESXi会跳过启动等待时间,去启动下一个系统。
为啥缩小容量呢?因为ESXi系统盘大小不够用了,新系统塞不进去(挠头
装了个Windows Server 2012 R2 Datacenter尝尝鲜,在本子上配置好之后觉得还挺香,遂打算扔服务器上,然后因为上面的原因卡住。
解决方法分两步。先声明一下,我是单磁盘系统,如果是多磁盘还得自己探索探索(
首先用Disk
Genius(其实系统自带的磁盘管理也行)打开vmdk磁盘,然后把系统分区缩小到目标容量,剩下的空间留空就行。完成后保存退出Disk
Genuis。
然后用随便一个文本编辑器打开vmdk文件,最上面几行有一行表示磁盘簇大小的,大小是磁盘容量(KB)的二倍,修改它到合适的大小就行。
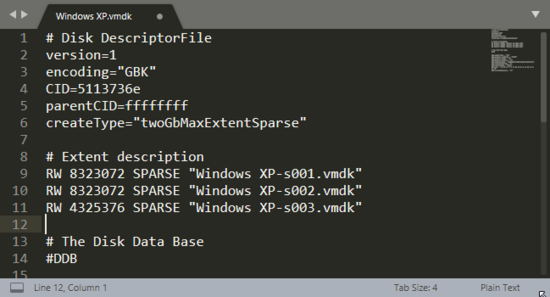
就是RW一行,改成合适的大小就行。
编辑完成之后直接用VMWare Workstation传到ESXi主机上就OK了。这一点不得不夸下,配套的东西确实挺好用。
折腾好服务器了,就得想想作何用途了。整理出来的大概有这些:
| Service | Description |
|---|---|
| gitea | 代码托管和CI/CD |
| cloudreve | 私有云,数据管理以及WebDAV数据备份同步 |
| minecraft | 这肯定必装啊,大型开放世界游戏(无误 |
| jupyter | 都装N卡了,不玩玩深度学习? |
| database | 当Web服务后端,香就一个字 |
| compile | 这可是56线程啊,我以后写个helloworld都要make -j56(大声 |
| calculate | 渲染和其他计算任务倒是可以试试丢上来跑 |
| vm server | 给别人也整几个虚拟机用用 |
| web services | 挂点WEB服务上去,岂不美哉 |
| mirror site | 整个镜像站,功德无量啊功德无量 |
| others | 后面再想 |
先配服务器再想应用场景,有一种先射击再瞄准的美
目前搭建的基本就是gitea, mc, cloudreve, jupyter, mysql这几个,后台还跑着一些运维脚本,目前这些已吃完我的内存了QAQ。总之简述下搭建流程吧。毕竟是个blog不是manual,就不贴太详细的步骤了。如果给出了指令,请确保在理解的情况下,按照真实系统环境执行。
这个搭建起来很简单,直接wget最新的build到你要安装的目录,然后把官方的service配置cat到/etc/systemd/system/gitea.service,再sudo systemctl enable --now gitea.service,之后再在给出的Web链接里配置好服务,最后修改好config.ini再重启服务就好了。
很好用的客户端
跟上面基本一样,先wget下来,再运行一下产生配置文件并修改好设置,并配置好systemd的服务管理,最后启动就行。不过,安装完成后,还得配置下存储策略来确定文件存储的物理位置,并在用户组中修改每种用户的空间限额大小和权限等。
这东西我最喜欢的点是支持WebDAV,所以配合上AutoSync之类的客户端,就能实现数据增量备份和同步。
喜闻乐见的MC时间。这边我是用Docker开服的,环境最干净,并且最方便于管理。具体参考以前写过的Docker-MC开服的博文。
这次为了运维简单,使用了某docker镜像来开服。官方服的唯一优点估计只剩下官方俩字了,实际表现可以说是一般环境一般,弱网环境逆天。据说原因是因为官方服务器只要丢包发生,无论几个都给你踢了。
所以建议用Paper之类的第三方服务端,性能好的多。
直接python3 -m pip install jupyterlab或者用apt, pacman之类的包管理器安装就行。装完了照着上面的在systemd把它添加为服务就行。装好之后,直接浏览器访问端口使用就行了。
唯一要注意的就是安全性了,注意设个复杂点的密码,小心暴力破解。
刚好这边有个项目得用数据库,所以就用docker开了个mysql的daemon当数据库。不得不说是真的方便
这部分我是用gitea-action搞定的。其他时候,我一般直接ssh到服务器上手动编译。不过注意,服务器的稳定性至关重要,别随便跑啥若治脚本把服务器玩炸了。数据可靠性很关键。特别是当你的服务器还挂了一堆存着重要数据的硬盘,要是真手欠rm -rf了你哭都没地方去。所以建议这种任务通通扔docker,反正没啥性能损失。
用JupyterLab能搞定一部分反正他们数据科学的基本全是python,另一部分相对需求较小的,就直接跑专门的计算进程算了。
由于计算任务的强性能需求和性能抢占特性,务必设置守护进程等手段,防止一个计算任务炸了整个服务器。
实在不行在ESXi再开个机器专门跑计算。(
打算先搓个轮子,然后基于这个轮子整个自动new container并绑定账号和tty的web service。安全性问题后面再说,这些机器可以用来租借或者提供给其他人学习使用。
比如可以把XDU-ISC的主页/blog挂上去,或者挂点其他Web服务,比如自动打卡之类的。
给各种大型镜像源整个分流,分担下压力造福开源——不过我这点硬盘容量就算了罢。
2023.11.03 昨天
Clash For Windows删库,今天clash core和其他Clash系的全部删库 哎 常用软件还是得整份源码小心删库 实在不行也能自己维护。
开个Samba给Windows共享用还是挺爽的。Win的Native WebDAV好像有点问题,不然就省事了。
详细配置教程可以参考Ubuntu tutorials - Install and configure samba。我搬个简略版的下来:
sudo apt update && sudo apt install samba
# 创建你要共享的目录
mkdir ~/sambashare
# 编辑samba配置文件
# 为了以命令形式展示这边用了古法编辑
# 建议用Vim/sed/nano之类的搞定
sudo cat << EOF >> /etc/samba/smb.conf
[sambashare]
comment = Samba on Ubuntu
path = /home/username/sambashare
read only = no
browsable = yes
EOF
sudo systemctl enable --now smbd && sudo service start samba
# 更改samba共享账户和密码
# 这个用户账户得是系统中现存的账户
sudo smbpasswd -a [username]
# 然后根据指引设定共享密码,完成完成后,从其他机器上以\\ip-address\sambashare就能访问共享的目录。
其他服务的话,比如我写的NanoOJ就可以挂上去给搞算法竞赛的小东西们训练用,也可以把我写那个XDU-Planet挂上去,聚合大家的博客黑历史博文,还能整点其他的花活。
最近把
XDU-Planet贡献给XDOSC社区了,目前挂了很多人的黑历史,可以来Planet看看。
总之,充分利用嘛。
哦对,这两天还搭建了个Overleaf用来写LaTex。把编译阶段的任务甩给服务器做挺爽的。部署指南参考了这篇步骤记录如下:
mkdir -p overleaf && cd overleaf
wget https://github.com/overleaf/overleaf/blob/main/docker-compose.yml
# 上边下下来compose配置之后得先改点地方,比如overleaf的端口,volume的存放路径等
docker-compose up -d
# 配置完整的TexLive以支持完整编译
docker exec -it sharelatex bash
cd /usr/local/texlive
wget http://mirror.ctan.org/systems/texlive/tlnet/update-tlmgr-latest.sh --no-check-certificate
sh update-tlmgr-latest.sh -- --upgrade
tlmgr option repository https://mirrors.ustc.edu.cn/CTAN/systems/texlive/tlnet
tlmgr update --self --all # luaotfload-tool -fu
tlmgr install scheme-full最下边的tlmgr install就是用来安装各种CTAN包的工具。以后有缺失的包时可以按需安装。
服务器的躯体是硬件,灵魂是数据。物理上的安全备份这里先不论,这里主要说说数据上的安全和管理。
磁盘上的数据无非就程序,配置和存储的重要数据文件这三类,下面分开说。
大部分程序只是一份可以重新安装下载的数据文件,所以我们只需要备份它的程序列表即可。在迁移系统或者出现重大损失时,我们只需要拿到程序列表,然后用你最喜欢的包管理器批量安装这些程序即可。假设你使用apt作为包管理器:前者可以通过dpkg --get-selections > backup.txt做到,后者可以通过sudo apt-get update && sudo apt-get install $(awk '{print $1}' backup.txt)做到。
当然,上面的实现只是最基础的。我们可以使用awk, git等工具把这件事做的更好。以上面两行脚本为基础原理,我们可以编写一个借助git进行备份记录的版本控制和备份,借助awk让备份的程序列表更加可读和强大,借助alias和bashrc为安装增加一个更新应用列表的hook,利用crontab实现备份的无人值守和自动化,并且可以增加应用的版本信息以及特定版本安装等等。
甚至,对于不在apt的软件,也可以手动记录,甚至是直接保存ELF到备份仓库中。
借助这个工具,灾难恢复也会变得相对简单。
TODO:后边实现这个脚本,先插个flag在这
Linux下的大多数配置文件因为都以一个点(dot)开头,所以也叫dotfile。我总结的最佳实践应该是利用Git和Hard-Link去进行管理。比较麻烦的是dotfiles的恢复,这个工作也可以写一个脚本完成,自动根据记录的配置文件路径(存储于csv文件中)去自动创建硬链接来管理。这个方法基本没啥问题,就是容易遇到各种莫名其妙的失效问题,以及在termux里边由于没有root权限不能创建符号链接就很难受。
这里有篇文章,讲解的更加详细:Best way to manage your dotfiles,也比较接近我的观念。还有这篇也值得参考:Best way to manage your dotfiles
参考上面的思路,对dotfiles的管理可以帮你在你电脑炸了的时候快速重建你的环境配置,以及回溯以前的配置文件,又或者是同步你的环境到其他机器上。舒适度拉满.jpg
这部分我做的最早。不过方案嘛,主打一个能用就行。
具体而言,首先在各个需要备份的目录下写一个backup.sh来生成要备份的文件,比如这个:
#!/bin/bash
FNAME="[backup]mc-server-$NAME-$(date +%Y%m%d%H%M%S).zip"
NAME="my-server"
zip -qr $FNAME $NAME/
echo $FNAME注意,必须输出生成的文件名称,后面有用。
然后随便找个地方写个脚本:
#!/bin/bash
# 使用Bash实现的自动备份工具
# 注意,绝对不能备份当前目录,不然会产生无限递归
BACKUP_DIR=$(dirname "$0")
set -e # 在出现错误时自动退出
set -u # 在使用未定义的变量时自动退出
set -o pipefail # 在管道中的任何一个命令出错时自动退出
while IFS= read -r line; do # 循环处理每一个备份任务
if [[ -z "$line" || "$line" =~ ^# ]]; then # 不执行注释和空行
continue
fi
# 使用awk得到任务参数
SOURCE=$(awk -F, '{print $1}' <<< "$line")
TARGET=$(awk -F, '{print $2}' <<< "$line")
MAX=$(awk -F, '{print $3}' <<< "$line") # 最大保留备份数量
echo "[$(date)] Backing up $SOURCE to $TARGET with max $MAX items"
cd "$SOURCE" && ./backup.sh | xargs mv -t "$TARGET"
echo "[$(date)] Backup source $SOURCE completed"
cd "$TARGET" && ls -t | tail -n +$((MAX+1)) | xargs rm -f
done < "$BACKUP_DIR/config.csv" # 备份任务配置数据位于脚本所在目录注释比较详细就不细说了。接下来在同级目录下touch config.csv来保存备份条目信息,举个例子:
# src,target,max-items
/home/xeonds/mc-server,/mnt/c/backup/mc-server-backup/atelier-of-zimin,4然后把上面的脚本加入crontab中定时运行:
0 4 * * * output=$(/home/xeonds/backup/backup.sh); pushplus "自动备份任务完成" "$output"上面的就是我正在用的的自动备份方案,pushplus参考我写的Bash学习笔记。
总体就突出一个刚好能用。
另外我记得好像推荐rsync做增量备份的来着,不过我的这些数据可能不太适合增量备份所以没用。如果是照片一类的文件,倒是很适合rsync来处理。回头可以抽空升级下这个脚本。
在继续阅读之前,永远保证数据安全,root的无上权限永远意味着使用者的责任,按下回车之前一定再三检查指令!!!
ssh username@server_ip "sudo dd if=/dev/sdX bs=4M status=progress" | dd of=/path/to/local/backup/server_root.img bs=4M上面的指令,将远端服务器的一个分区直接备份到本地的一个文件中,块级别拷贝,安全可靠,就是dd指令特别危险,得谨慎使用。
还原的时候,在目标计算机上启动Live CD进入一个临时系统,挂载磁盘然后用合适的指令还原数据:
dd if=/path/to/local/backup/server_root.img bs=4M status=progress | ssh username@new_server_ip "sudo dd of=/dev/sdY bs=4M status=progress"如果是同一服务器备份还原,那还原之后直接用就行了。但是如果服务器硬件不一致的话,那就得重新配置一些东西了。
我用的是GRUB,解决方案如下。基本就是重新安装然后更新引导项。
# Assuming /mnt is the mount point of the restored system
sudo mount /dev/sdY1 /mnt # Mount the root partition
sudo mount --bind /dev /mnt/dev
sudo mount --bind /proc /mnt/proc
sudo mount --bind /sys /mnt/sys
sudo chroot /mnt /bin/bash
grub-install /dev/sdY
update-grub
exit使用dd恢复有一个问题,就是如果新的系统盘变大了,那还原之后系统可能还以为大小和以前一样。这种情况就需要:
sudo resize2fs /dev/sdY1
df -h # check whether the disk size covers the entire partition完事之后可能还需要用gparted之类的东西变一下磁盘大小。
这玩意其实其他地方也会需要,比如硬盘UUID因为各种玄学原因变化了。
sudo blkid /dev/sdY1
sudo vi /etc/fstab # 更新其中对应设备的UUID另外就是如果在/etc/default/grub里边的GRUB_CMDLINE_LINUX里边也指定了,那也得改成对应的。改完之后sudo update-grub。
完事重启,应该就能正常使用了。
如果服务器是全新安装,并且采用UEFI启动的话,那必须手动重建EFI分区,而且它得是硬盘的第一个分区。详细参考这里:全新安装 - archlinux简明指南
不过我自己迁移的时候因为几块硬盘倒来倒去太麻烦,索性就直接重装系统了。迁移之后,对于之前的数据恢复,找到那个备份生成的.img文件,用下面的指令挂载然后恢复数据就行:
sudo mount -o ro,noload server-old.img ./old/上面的镜像和要挂载的目录改成你自己需要的就行。要迁移的项目就下面几个:
| 名称 | 路径 |
|---|---|
| crontab | /etc/cron.*/和crontab -l的内容 |
| home下的各种服务 | ~/ |
| 各种自定义脚本 | /usr/local/bin |
首当其冲就是硬盘安全。这方面可以用smartctl来定期监测SMART信息确认磁盘状态。我试了下,好像ESXi里边我映射的硬盘也支持检测SMART信息。这里也可以写个脚本定期监测并发送监测报告此处可本。
天天脚本脚本,那么
你们程序员移一定都是足控吧.jpg
其他的嘛……暂时莫得啥需求。
很喜欢Bash的一句话:man bash。
如何整理磁盘上的文件?问问mv, cp, ls, rm, cat, grep, sed, awk, xargs;然后,用bash把它们拼起来就行。只要你想,你可以编写出任何脚本来整理你的所有文件。
TODO:具体的脚本太多了,这里地方小,写不下(溜
2024.1.4:update
很早之前就整上这个Windows Server 2012 R2数据中心版本了,之前一直纯当Windows用的,今天发现Windows Server Datacenter确实是有一些很便利数据中心管理的feature,其中最让我心动的无疑是它的Deduplication功能。这个部分作为服务器的可选功能,需要在服务器管理面板手动添加,而且微软的东西的一个好处就是文档有中文而且相对比较完善,参考安装和启用数据删除。虽然上边标注的适用版本里边好像没有Windows Server 2012 R2 Datacenter,但是我自己实测是支持这个版本的。
具体的开启步骤上面的参考链接里边有,这里说下我的踩坑经历。首先就是这玩意的文件系统只支持NTFS和ReFS两种,并且必须是本地的磁盘(但是我主力Linux,而且文件比较乱,还没把磁盘重新分配给Windows),也就是说必须在ESXi里边把磁盘分配给Windows才能享受数据压缩。其次就是这个压缩是以块为粒度的,根据微软官方的说法而言,能够节省的空间确实不少,适合文件服务器和给Hyper-V服务器用,能显著节省空间。另外这个玩意是个定期运行的服务,服务的注意事项它也得注意。
以及除了这个本体之外,还有一个ddpeval.exe是用来评估数据压缩效果的。可以先跑一次这个然后再根据实际情况决策是否启用数据压缩。还有就是这东西作为重型I/O操作,很吃内存和CPU,所以启用数据去重服务的时候得注意根据实际情况限制它可以使用的资源量。
哎,要是这玩意有开源实现就好了,直接挂Linux底下定期执行。
都Linux了不得写个脚本帮自己干活?而且还有其他好用的工具呢,首当其冲的还得是systemctl,crontab,一个自动管理后台服务,一个自动运行任务,堪称运维两大法器。systemctl多用来自动启动和重启后台服务,crontab作为一个定时器,基本跟时间相关的任务都能干,比如自动报时,定时清理,定时重启,定时更新,定时打卡,定时发送状态简报,定时发送邮件,定时煮饭等等你能想到想不到的。
另外,还有bash和alias,前者不光能跟你打交互,还能连接很多强大的工具;后者不光是个别名,还能帮你hook各种命令,给它们加点小功能。这部分建议多读读命令行的艺术,以及man bash的内容,更重要的是得多用。
我整完这些之后,感觉还是不太过瘾。毕竟这些功能全能点的面板估计也能做到,而且我也不可能到处因为一点小事就ssh到服务器上吧)
在接触了低代码表单的思想之后,我就又想造轮子了:搓个工具,借助低代码系统,写出自己的运维管理面板,最好是实现一个页面一个配置文件,改配置文件就更新对应页面和后面调用的命令的程度。
借助这个工具倒是可以实现很轻量,而且完全自由的服务器控制面板,而且无需依赖,可定制度拉满那种。
TODO:这里也挖个坑立个flag
上面那段倒是偏离自动运维这个话题了。说回正题:除了上面提到的systemd和crontab之外,还可以让系统监听一些事件,并做出即时响应。
这里先放个UNIX哲学()
比如让系统读取某进程的日志输出,如果输出带有ERROR等字样,就发送警告给运维,或者执行其他的动作。,我们可以将触发的部分和执行的部分分离,让系统对不同的问题做出响应。比如收到了内存不足的警报,那就自动执行sudo echo 3 > /proc/sys/vm/drop_caches来释放内存,还是过高的话就报警并随机kill一个幸运进程;比如有个若治同事又把你数据库炸了给你发邮件求助,那系统就直接roll
back数据库;再比如监测到系统设备panic了,直接发送警报并紧急关机系统防止进一步损失;还可以接收UPS的断电信号,发送警报并迅速关机来避免更大的损失;有什么登录失败的/疑似端口爆破的,直接自动ban了它的IP;再比如系统流量激增,直接报警;再比如ban了sudo rm -rf /这种敏感操作;甚至自动审核各种请求等等。只有想不到,没有做不到除了生孩子。
这里重点介绍下Systemd。其中的工具对于自动化运维来说很常用。大多是现代linux都内置了systemd的相关组件,并使用systemd-init替换了原来的sysv-init作为系统引导服务。
Systemd是一组工具合集,其中包含了70多个常用的系统基础工具,覆盖系统服务管理,系统启动管理,网络管理,计划任务等等。
首先值得注意的是systemd对待$()的行为。在bash中,这个符号表示执行括号中的命令,并将这个命令原地替换为执行的结果;但是在systemd中,它的行为和makefile中一致:表示变量引用。因此,在编写systemd服务时注意含义区别。
另外就是单元文件存储的位置。单元可以分为三类,一类是系统级单元,一类是本地管理员管理的系统级单元,一类是用户级单元。三类单元分别是系统启动时使用的单元,以系统权限运行的单元,以及非特权用户级别运行的单元,路径分别位于:
/lib/systemd/system//etc/systemd/system//etc/systemd/user/ 或
~/.config/systemd/user/systemd-timer 是 systemd
中的一个重要组件。它允许用户定义和管理定时任务,使得系统能够在预定时间执行特定的操作。作为crontab的替代品比较不错,有完善的日志支持,统一的服务管理,依赖管理等。
systemd-timer
使用单元文件(unit
files)来描述要执行的定时任务。定时器单元文件的命名规则为
.timer,通常位于 /etc/systemd/system/
目录下。以下是一个简单的定时器单元文件的示例,用于每天执行一个备份任务:
[Unit]
Description=Backup Timer
[Timer]
OnCalendar=daily
Persistent=true
[Install]
WantedBy=timers.target[Unit] 部分描述了定时器的基本信息。[Timer]
部分定义了定时器的执行计划。在这个示例中,OnCalendar=daily
表示每天执行一次任务。[Install] 部分定义了单元文件的安装信息。sudo systemctl start mytimer.timersudo systemctl stop mytimer.timersudo systemctl status mytimer.timerjournalctl -u mytimer.timer持久性定时器 通过设置
Persistent=true,可以使定时器在错过预定执行时间后立即触发任务执行。这对于保证任务的执行是非常有用的。
使用 OnCalendar 属性 OnCalendar
属性允许您以灵活的方式定义定时器的执行时间。您可以指定特定的日期、每周、每月甚至每小时执行任务的时间。
#### systemd-service
服务管理器是systemd中最核心的部分之一。systemd 的服务管理器允许用户管理系统上运行的服务,这些服务可以是系统进程、网络服务、后台任务等等。
.service
扩展名结尾,其中包含了服务的配置信息以及其行为。服务单元文件通常位于
/etc/systemd/system/ 目录下,但也可以位于其他位置。下面是一个简单的示例服务单元文件,用于启动一个假设的 Web 服务器:
[Unit]
Description=My Web Server
After=network.target
[Service]
ExecStart=/usr/bin/my_web_server
Restart=always
[Install]
WantedBy=multi-user.target[Unit]
部分描述了单元的基本信息,如描述和依赖关系。[Service] 部分定义了服务的执行方式和行为。[Install] 部分定义了单元文件如何被安装。sudo systemctl start servicenamesudo systemctl stop servicenamesudo systemctl restart servicenamesudo systemctl status servicenamesudo systemctl enable servicenamesudo systemctl disable servicename日志和故障排除 可以使用 journalctl 命令来查看
systemd 的日志信息,例如:journalctl -u servicename
将显示特定服务的日志。
高级功能
Requires 和 After
来定义服务之间的依赖关系。Requires
指定了其他单元,表示该服务依赖于指定的单元;After
则指定了在何时启动该服务。[Unit]
Description=My Service
Requires=network.target
After=network.target通过在服务单元文件中使用 LimitCPU,
LimitMEM, LimitNOFILE
等参数,可以限制服务的资源使用。这有助于防止某个服务占用过多的系统资源。
[Service]
LimitCPU=50%
LimitMEM=512M
LimitNOFILE=10000有时,服务需要使用特定的环境变量才能正常运行。您可以在服务单元文件的
[Service] 部分中使用 Environment
参数来设置这些环境变量。
[Service]
Environment="VAR1=value1"
Environment="VAR2=value2"最近升级成32G DDR4 ECC内存了,所以想着也不用swap了于是就关了:
sudo swapoff /swap.img # 这里需要改成你的swap文件
# sudo rm /swap.img # 可选至于关不关,区别似乎不大,但是确实节省了我一些磁盘空间,理论上能延缓磁盘使用寿命。具体还是得看服务器日常内存占用情况而决定。
服务器平时总是空着的,所以打算把服务器给几个哥们也分配个号。想来想去虚拟化的话性能损耗比较大,不如上用户组来进行权限管理,刚好也多一个深入学习Linux系统的机会。
首先是创建用户组:sudo groupadd dim0,创建完成后再更改用户组权限即可。
然后是创建所有用户:for user in {tesla,zimin,holynia,ray}; do sudo useradd -m -G dim0 $user; done,创建用户的同时,将他们加入dim0用户组,并且自动为他们创建用户目录。
完成之后就是修改用户组的权限了。他们创建的时候就不在wheel用户组中,所以没有sudo权限。
对于需要禁止访问的目录,更改权限和所有权就行:
sudo chown xeonds:wheel /path/2/dir
sudo chmod go-x /path/2/dir到这里,我的服务器就基本折腾好了。我现在拥有一个数据安全性相对较高的NAS,一个日常开发可用的自动化编译/部署服务,一个代码托管和备份系统,一个7x24可用的mc服务器,一个可用于数据科学/AI学习的在线算力,一个可以随时启动的,一个可以租借给他人的docker vm实例集群,甚至是一个会自己维护自己,会帮我处理各种浪费时间的重复任务,并且易于灾难恢复和迁移的系统,以及一个Linux新手应该具备的系统管理心得经验。
可以说,这些投入,物超所值。